华球网点击下图进入官网:

华球网点击下图进入活动:

华球网点击下图进入领取彩金:

赌博公司亚洲首选288x|http://dbgsyzsxxpnxs.weebly.com
武松国际|http://wsgjgwye.weebly.com
小鱼儿玄机2站|http://xyexjziacw.weebly.com
老虎机送话费|http://lhjshfahae.weebly.com
优发娱乐平台|http://yfylptxyki.weebly.com
优乐娱乐|http://ylylbntw.weebly.com
0px; border-image: initial">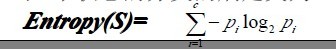
2、信息增益度量期望的熵降低
信息增益Gain(S,A)定义
已经有了熵作为衡量训练样例集合纯度的标准,现在可以定义属性分类训练数据的效力的度量标准
0008全讯白菜。这个标准被称为“信息增益(information gain)”。简单的说,一个属性的信息增益就是由于使用这个属性分割样例而导致的期望熵降低(或者说,样本按照某属性划分时造成熵减少的期望)。更精确地讲,一个属性A相对样例集合S的信息增益Gain(S,A)被定义为:

其中 Values(A)是属性A所有可能值的集合,是S中属性A的值为v的子集。换句话来讲,Gain(S,A)是由于给定属性A的值而得到的关于目标函数值的信息。当对S的一个任意成员的目标值编码时,Gain(S,A)的值是在知道属性A的值后可以节省的二进制位数。
接下来,有必要提醒读者一下:关于下面这两个概念 or 公式,
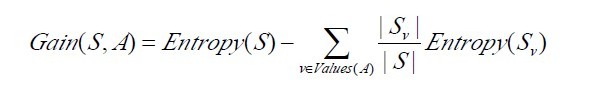
下面,举个例子,假定S是一套有关天气的训练样例,描述它的属性包括可能是具有Weak和Strong两个值的Wind。像前面一样,假定S包含14个样例,[9+,5-]。在这14个样例中,假定正例中的6个和反例中的2个有Wind =Weak,其他的有Wind=Strong。由于按照属性Wind分类14个样例得到的信息增益可以计算如下。
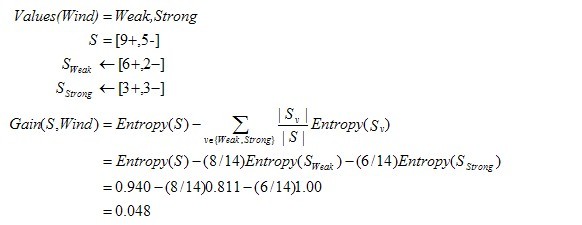
运用在本文开头举得第二个根据天气情况是否决定打羽毛球的例子上,得到的最佳分类属性如下图所示:
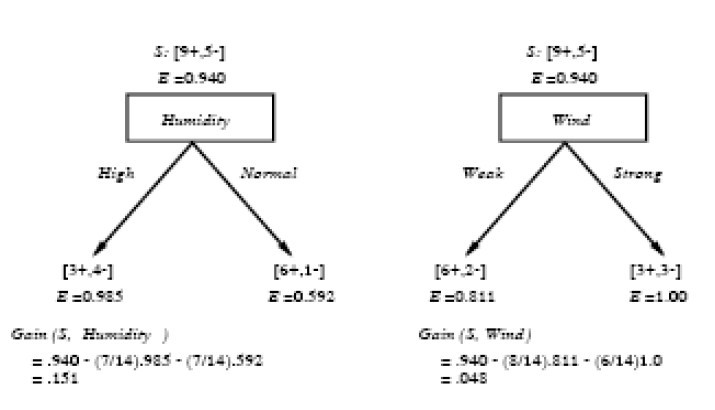
在上图中,计算了两个不同属性:湿度(humidity)和风力(wind)的信息增益,最终humidity这种分类的信息增益0.151>wind增益的0.048。说白了,就是在星期六上午是否适合打网球的问题诀策中,采取humidity较wind作为分类属性更佳,决策树由此而来。
OK,下图为ID3算法第一步后形成的部分决策树。这样综合起来看,就容易理解多了。1、overcast样例必为正,所以为叶子结点,总为yes;2、ID3无回溯,局部最优,而非全局最优,还有另一种树后修剪决策树。下图是ID3算法第一步后形成的部分决策树:
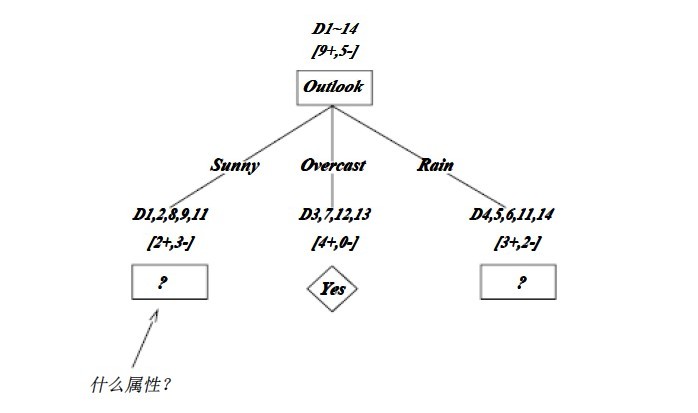
如上图,训练样例被排列到对应的分支结点。分支Overcast的所有样例都是正例,所以成为目标分类为Yes的叶结点。另两个结点将被进一步展开,方法是按照新的样例子集选取信息增益最高的属性。
C4.5,是机器学习算法中的另一个分类决策树算法,它是决策树(决策树也就是做决策的节点间的组织方式像一棵树,其实是一个倒树)核心算法,也是上文1.2节所介绍的ID3的改进算法,所以基本上了解了一半决策树构造方法就能构造它。
决策树构造方法其实就是每次选择一个好的特征以及分裂点作为当前节点的分类条件。
既然说C4.5算法是ID3的改进算法,那么C4.5相比于ID3改进的地方有哪些呢?:
- 用信息增益率来选择属性。ID3选择属性用的是子树的信息增益, 开心8这里可以用很多方法来定义信息,ID3使用的是熵(entropy,熵是一种不纯度度量准则),也就是熵的变化值,而C4.5用的是信息增益率。对,区别就在于一个是信息增益,一个是信息增益率。
- 在树构造过程中进行剪枝,在构造决策树的时候,那些挂着几个元素的节点,不考虑最好,不然容易导致overfitting。
- 对非离散数据也能处理。
- 能够对不完整数据进行处理
针对上述第一点,解释下:一般来说率就是用来取平衡用的,就像方差起的作用差不多,比如有两个跑步的人,一个起点是10m/s的人、其10s后为20m/s;另一个人起速是1m/s、其1s后为2m/s。如果紧紧算差值那么两个差距就很大了,如果使用速度增加率(加速度,即都是为1m/s^2)来衡量,2个人就是一样的加速度。因此,C4.5克服了ID3用信息增益选择属性时偏向选择取值多的属性的不足。
C4.5算法之信息增益率
OK,既然上文中提到C4.5用的是信息增益率,那增益率的具体是如何定义的呢?:
是的,在这里,C4.5算法不再是通过信息增益来选择决策属性。一个可以选择的度量标准是增益比率gain ratio(Quinlan 1986)。增益比率度量是用前面的增益度量Gain(S,A)和分裂信息度量SplitInformation(S,A)来共同定义的,如下所示:
其中,分裂信息度量被定义为(分裂信息用来衡量属性分裂数据的广度和均匀):
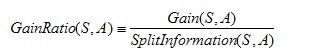
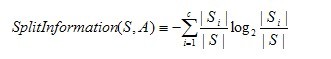
其中S1到Sc是c个值的属性A分割S而形成的c个样例子集。注意分裂信息实际上就是S关于属性A的各值的熵。这与我们前面对熵的使用不同,在那里我们只考虑S关于学习到的树要预测的目标属性的值的熵。
请注意,分裂信息项阻碍选择值为均匀分布的属性。例如,考虑一个含有n个样例的集合被属性A彻底分割(译注:分成n组,即一个样例一组)。这时分裂信息的值为log2n。相反,一个布尔属性B分割同样的n个实例,如果恰好平分两半,那么分裂信息是1。如果属性A和B产生同样的信息增益,那么根据增益比率度量,明显B会得分更高。
使用增益比率代替增益来选择属性产生的一个实际问题是,当某个Si接近S(|Si|?|S|)时分母可能为0或非常小。如果某个属性对于S的所有样例有几乎同样的值,这时要么导致增益比率未定义,要么是增益比率非常大。为了避免选择这种属性,我们可以采用这样一些启发式规则,比如先计算每个属性的增益,然后仅对那些增益高过平均值的属性应用增益比率测试(Quinlan 1986)。
除了信息增益,Lopez de Mantaras(1991)介绍了另一种直接针对上述问题而设计的度量,它是基于距离的(distance-based)。这个度量标准基于所定义的一个数据划分间的距离尺度。具体更多请参看:Tom M.Mitchhell所著的机器学习之3.7.3节。
1.3.2、C4.5算法构造决策树的过程
1.3.3、C4.5算法实现中的几个关键步骤
在上文中,我们已经知道了决策树学习C4.5算法中4个重要概念的表达,如下:
